

LLMs Don’t Cut it For Data Analytics
But They Might Help With Discovery
%202.png)
Introduction
I was fortunate enough to attend my second Snowflake Summit in San Francisco a few weeks ago. As before, I was impressed by the energy, conversations, and overall excitement that emerges when the data community gets together.
One conversation I found myself repeating multiple times with prospects revolved around the theme of leveraging large language models (LLMs) for data analytics. After four days of having these conversations and hearing the perspectives of hundreds of data leaders who are also contemplating this topic - I realized that a blog post would be the best way to open the conversation to more people.
AI is fueling dreams across the data ecosystem. Perhaps the most widespread dream is that of an AI that can answer all data-related questions, such as "How have my organization's sales evolved in the past 10 weeks?" or "What should I do to improve revenue?”
This vision manifests in various way:
“You understand, it would allow the marketing and sales team to make better decisions”
“I could scale the data culture in my company, without having to scale my data team”
“For the first time, my data team could finally focus on important tasks instead of acting as support”
And because the world is a remarkable place, vendors in the exhibition hall all promised to deliver on this dream. As I roamed the exposition hall in search of a lemonade, I encountered countless mentions of "AI-Powered Analytics," "AI-native Analytics," and so on. At CastorDoc, where AI has been a priority for the past year, we are also contemplating how to make this dream a reality.
Before the Snowflake Summit, part of me felt uneasy about AI features. Were people going to use them? Was AI a push from vendors or is there actual demand? The summit dispelled my doubts. The enthusiasm for AI is palpable, with users actively seeking these capabilities.
In this post, I'll examine the two primary approaches to implementing AI in data analytics, discussing the pros and cons of each and highlighting key considerations for both solutions.
I - LLMs for Data Analytics
The first approach consists in leveraging LLMs to perform data analysis. The process goes as follows:
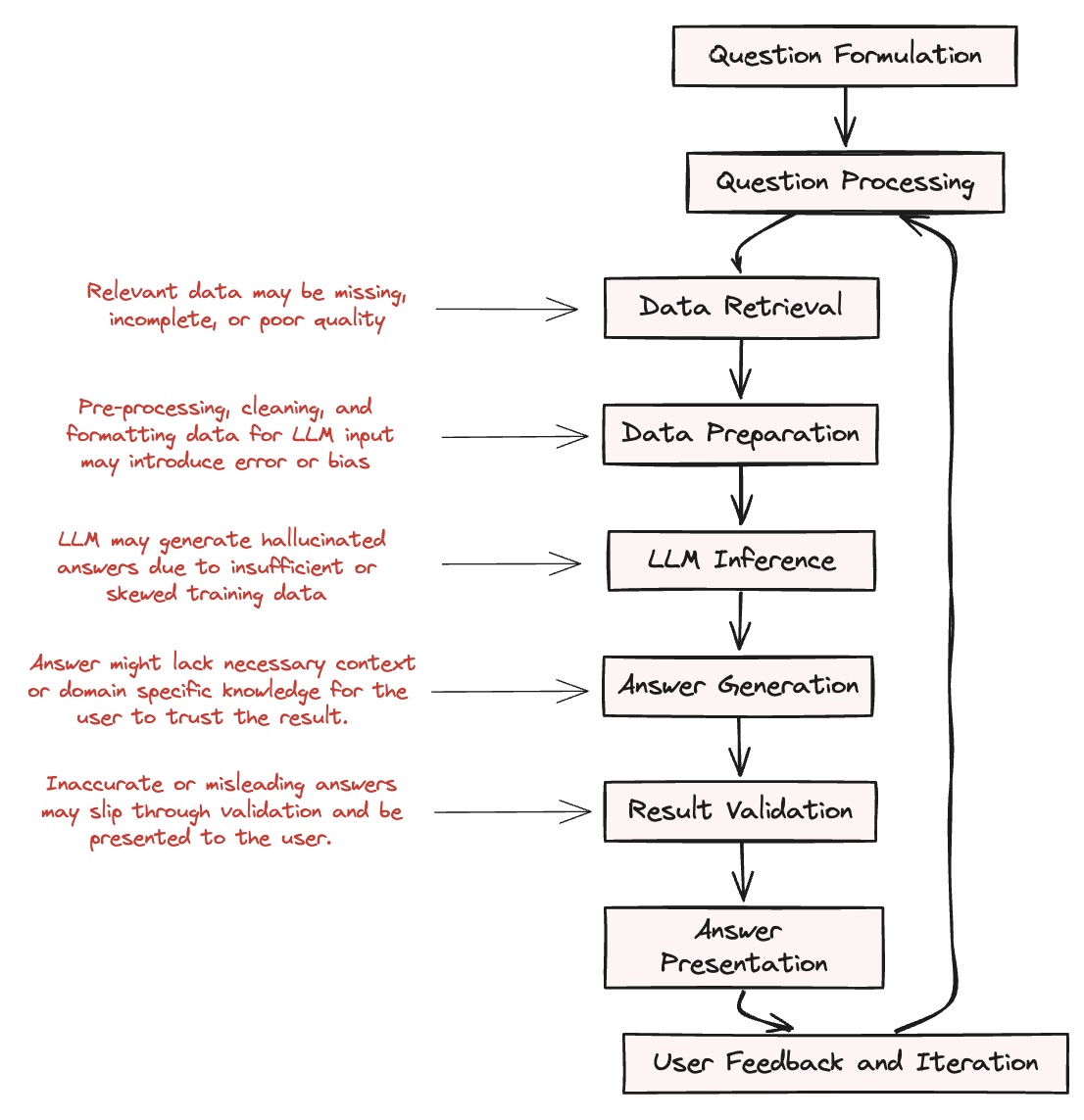
It starts with the user asking a question in natural language. The question is preprocessed and tokenized to make it compatible with the large language model (LLM). Relevant data is then retrieved from identified sources, preprocessed, cleaned, and formatted as input for the LLM.
The prepared question and data are fed into the LLM for processing. The LLM's output is post-processed into a human-readable answer, which is validated against the original question for accuracy. Finally, the answer is presented to the user, potentially with visualizations. The user can then review the answer, provide feedback, and ask follow-up questions, initiating another cycle of the process if needed.
This approach is attractive because it provides a turnkey solution (or "clé en main" as we say in French) that delivers answers directly to end users. However, it's not without its challenges. What if users can't trust the generated results? There's a risk of spreading false information across the entire organization. And if this were happening, how would you even know? These questions highlight the need for careful implementation and ongoing monitoring of LLM-based data analysis systems.
Let's delve into some specific downsides of this approach:
- Data Retrieval: Relevant data may be missing, incomplete, or of poor quality, leading to inaccurate analysis, while LLMs may also retrieve irrelevant, outdated, or sensitive data that should not be used.
- Data Preparation: Preprocessing, cleaning, and formatting data for LLM input may introduce errors or bias, and important details may be lost during the process.
- LLM Inference: LLMs may generate incorrect, biased, or hallucinated answers due to insufficient or skewed training data, and they may struggle with complex reasoning or domain-specific knowledge.
- Answer Generation: Generated answers may lack necessary context, explanations, or actionable insights for the user and may not be easily interpretable or directly address the original question.
- Result Validation: Validating LLM-generated answers against the original question may be challenging, especially for complex queries, and inaccurate or misleading answers may slip through validation and be presented to the user.
- Answer Presentation: The presentation of the answer may be confusing, unclear, or lack necessary visualizations to aid understanding, leading to users misinterpreting or misapplying the presented insights.
II - Start with Natural Langage Search and Asset Curation
While LLMs for end-to-end data analytics show promise, they're not quite there yet. Let's consider the real problem at hand: when a user asks a data question, do they typically need:
- To generate a new piece of analysis from scratch?
- To find an existing, trustworthy piece of analysis, and surface it to the right person, at the right time?
More often than not, it's the latter. This is where our second approach comes in, leveraging LLMs for natural language search and asset curation rather than from-scratch analysis.
Here’s how it works:

The user formulates a question, which is then processed and tokenized for compatibility with the LLM. The LLM then searches for existing analytics assets that may answer the question. The LLM always search for the most finished analytics asset that exists. The most finished piece of analysis is usually a dashboard. If a relevant dashboard is found, it is selected, and an explanation is generated to present the dashboard asset to the user.
If no suitable dashboard is found, the LLM suggests the most relevant table(s) for analysis, provides guidance on the type of analysis needed, and recommends a SQL or other query language code to perform the suggested analysis on the identified table(s). The user can then execute the recommended query to derive the desired insights.
This approach focuses on leveraging the LLM's natural language capabilities to bridge the gap between user questions and existing analytics assets within the organization, rather than attempting to generate new analyses from scratch.
This approach presents many advantages, amongst which:
- Efficient resource use: LLMs can surface existing analytics assets, saving time and resources that would otherwise be spent recreating analyses.
- Improved accuracy: Existing assets are created by experts and vetted for accuracy , ensuring sound decision-making.
- Business knowledge alignment: Pre-existing assets are already tied to the company's business concepts.
- Enhanced data governance: Using existing assets helps maintain better control over data security, privacy, and compliance.
- Scalability: Natural language search democratizes access to insights across the organization without extensive training.
- Cost-effectiveness: Maximizing use of existing assets reduces the need for additional investments and minimizes risks associated with LLM token-based pricing.
By acting as a bridge between users and available analytics assets, this method significantly enhances the value of an organization's analytics investments, connecting people with the right insights at the right time.
Conclusion
As we've explored, the integration of LLMs in data analytics presents both exciting possibilities and challenges. While the dream of AI-powered, end-to-end data analysis is enticing, current limitations suggest a more pragmatic approach.
We've looked at two primary strategies:
- Using LLMs to perform direct data analysis
- Leveraging LLMs for natural language search and asset curation
The second approach, focusing on surfacing existing analytics assets, offers a more immediately viable and valuable solution. It balances the power of AI with the reliability of human-created, vetted analyses, while addressing key concerns around accuracy, efficiency, and data governance.
.png)
You might also like
%202.png)



%203.png)



Get in Touch to Learn More


“[I like] The easy to use interface and the speed of finding the relevant assets that you're looking for in your database. I also really enjoy the score given to each table, [which] lets you prioritize the results of your queries by how often certain data is used.” - Michal P., Head of Data
